

[Note: This blog post will be updated after the release of Spring ’21 to mention updates to the capability of record triggered flows.]
In Summer ’20, Salesforce is releasing the after record save flow trigger. This joins the before record save flow trigger introduced in Spring ’20. In introduction of these two flow features is the start to moving automation from multiple tools (process builder and flow builder) to flow builder. I consider these features MVP and need further enhancements to get it to them to the point where you can really truly start transitioning your processes to flow.
With the introduction of the after record save flow trigger feature (the equivalent to a process built in process builder), I wondered how close this feature was to replacing process builder.
I build my processes using the best practices of apex triggers – one trigger per object. I build one master process per object. Given that design, my processes normally handle both situations – record creation and record update.
So, I wanted to see if I can build an after record save flow trigger to cover both situations. Unfortunately, I hit roadblocks immediately.
There was no way for me to determine whether a record is new (I can use the IsNew() syntax in my process criteria node). Since the new record is already created, I can no longer use the $Record and specifically, to see whether the $Record.Id was null as I can in a before record save flow trigger. In a before save, the record does not yet exist in the database, therefore, if the id is null, it would signify a new record.
For existing records, I still cannot determine whether a field has changed (using the IsChanged() or PriorValue() syntax as I do in my process criteria node). Because this is an after save function, I cannot query the record for its current values for comparison as I can with a before record save flow trigger. (Thanks, Gorav Seth for your blog post.) I don’t know about you, but I do not want my automation to run every time the record is updated and the field equals a specific value. I only want it to execute if the field is changed.
You also cannot call a subflow in an after record save flow trigger. It is not efficient to build a complex flow in your after record save flow trigger and not maintain this in its own flow.
I have to admit, I was disappointed.
So, I thought, can this possibly work to handle situations for when a new record is created.
I took a fairly simple process on record save only and looked into whether it would be feasible to convert the process built in process builder and built that same automation using the new summer ’20 after new record save flow trigger.
Here is my process for a new case:

The first criteria checks to see if the case origin is web. If true, it will update the priority of the record to high.
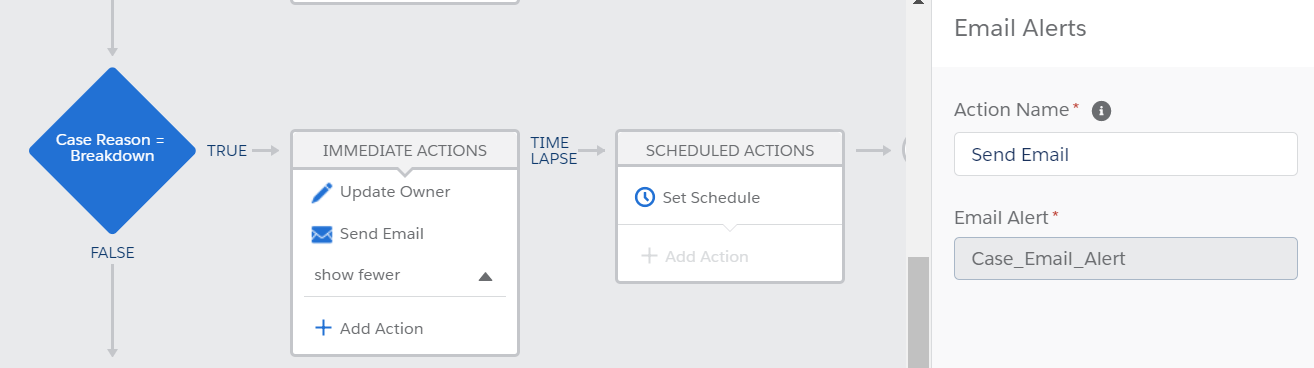
The second criteria checks if the case reason is breakdown. If true, it will update the case ownership to a specific case queue and to send an email alert.
I was able to build this automation in flow builder.


Let’s walkthrough each process builder element and how this translated to flow.
In process builder, after you specify the process starts when a record changes, you specify the object (Case) and that it starts only when a record is created.

In flow builder, you create a record-changed flow and then you specify to trigger the flow when the record is created and to run the flow after the record is saved.
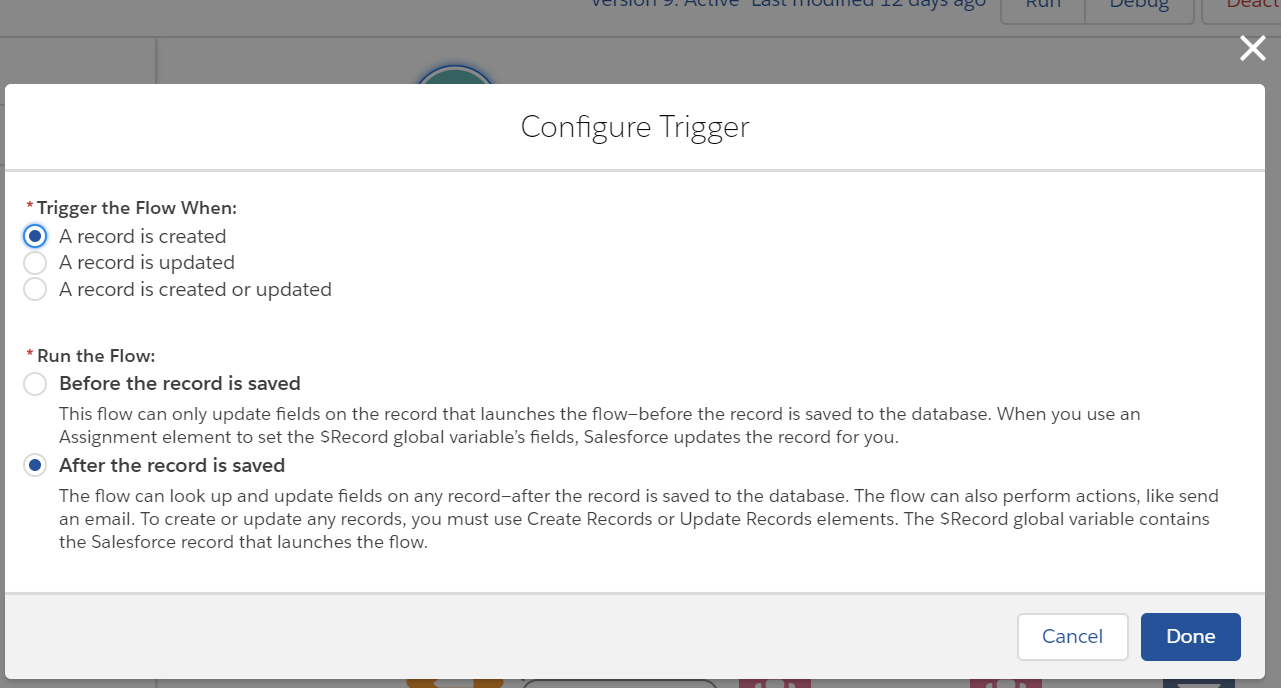
Then, you select the object (Case) that triggers the flow.
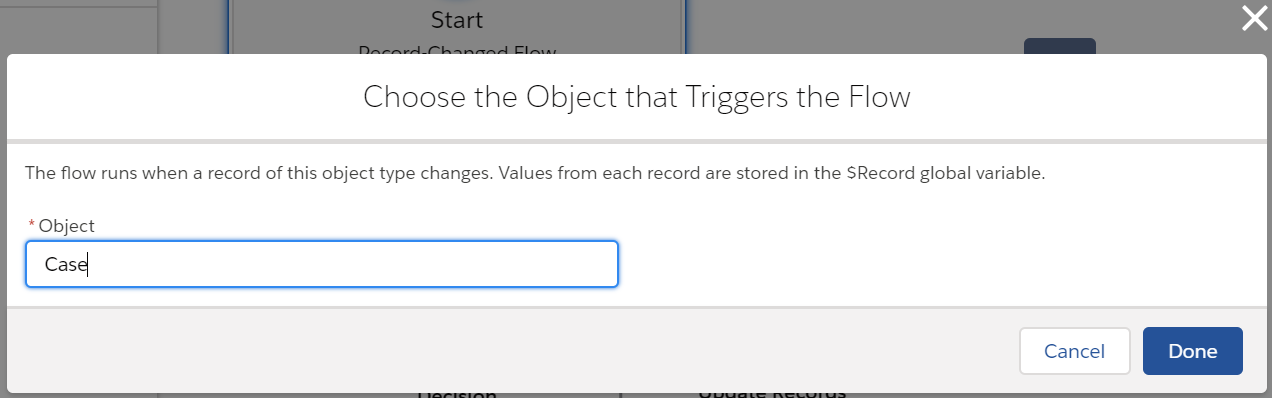
Now, lets take a look at the first criteria node…In process builder, we set the condition to [Case].Origin Equals Picklist Web.

In flow builder, we need to create a Decision flow element. The condition for the “Case Origin is Web” outcome here is {!Record.Origin} Equals Web. Note: Any record attributes are found using $Record global variable. The default outcome is “Case Origin is Not Web.” Note: The default outcome is equivalent to the false condition in process builder.

Now, let’s look at the immediate action in process builder to update the record that started the process to update the priority to high: Priority Picklist High.

Switching over to flow builder, for the “Case Origin is Web” outcome, we need an Update Records flow element. Configure it as follows:
- How to Find Records to Update and Set Their Values: Specify conditions to identify records, and set fields individually
- Object: Case
- Condition Requirements: Conditions are Met where Id Equals {!Record.Id}
- Set Field Values for Case Records: Priority: High

At the end of the first criteria node in process builder, we set it to evaluate the next criteria.

In flow builder, the equivalent function is done with a regular connector from the Update Records flow element to the next decision (i.e. “criteria node”).
Now, for the second criteria node in process builder, Case Reason = Breakdown, we set the conditions to [Case].Reason Equals Picklist Breakdown.

In flow builder, we need to create another Decision flow element. The condition for the “Case Reason is Breakdown” outcome here is {!Record.Reason} Equals Breakdown. As mentioned above, any record attributes are found using $Record global variable. The default outcome is “Case Reason is Not Breakdown.” Note: The default outcome is equivalent to the false condition in process builder.

For the immediate action in process builder, we want to update a field for the record that started the process: Owner ID Queue Jen_Queue.

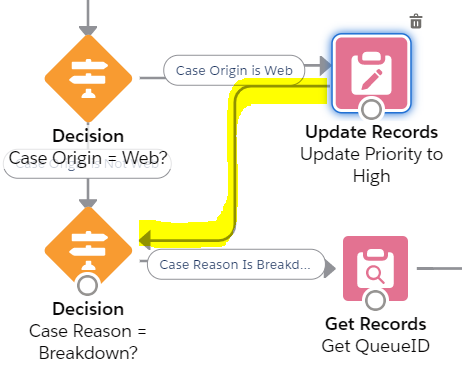
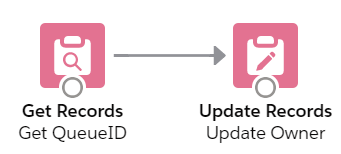
Switching over to flow builder, this one step in process builder will require two flow elements for the “Case Reason is Breakdown” outcome: Get Records flow element and Update Records flow element to update the owner Id to the queue Id.
In the Get Records flow element, we need to get the queue Id based on the queue name. We need the Id to update the owner id. We can’t just reference the queue name.
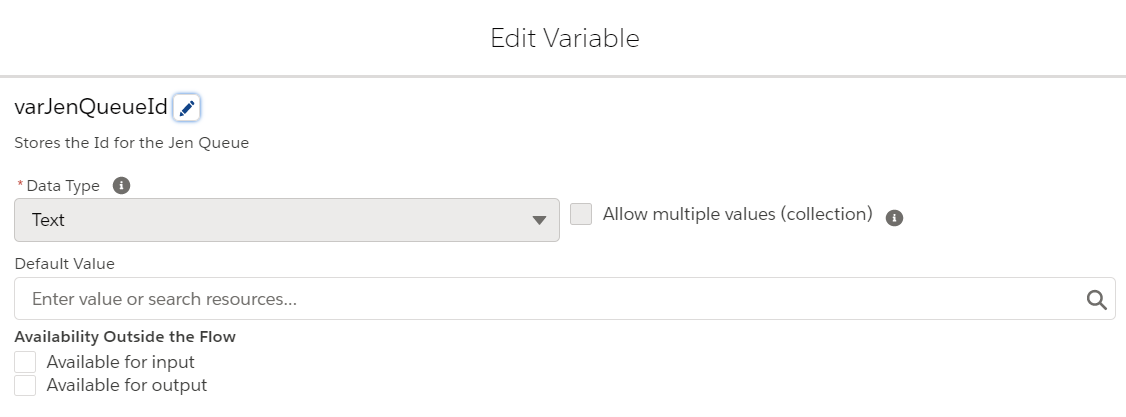
We first need to create a text variable to store the queue Id. Configure as follows:
- Variable name: varJenQueueId
- Data Type: Text
Configure the Get Records flow element as follows:
- Object: Group
- Condition Requirements: Conditions are Met where DeveloperName Equals Jen_Queue
- How Many Records to Store: Only the first record
- How to Store Record Data: Choose fields and assign variables (advanced)
- Where to Store Field Values: In separate variables, Id: {!varJenQueueId}

Next, we use the Update Records flow element to update the owner Id to the queue Id. Configure it as follows:
- How to Find Records to Update and Set Their Values: Specify conditions to identify records, and set fields individually
- Object: Case
- Condition Requirements: Conditions are Met where Id Equals {!Record.Id}
- Set Field Values for the Case Records: OwnerId: {!varJenQueueId}

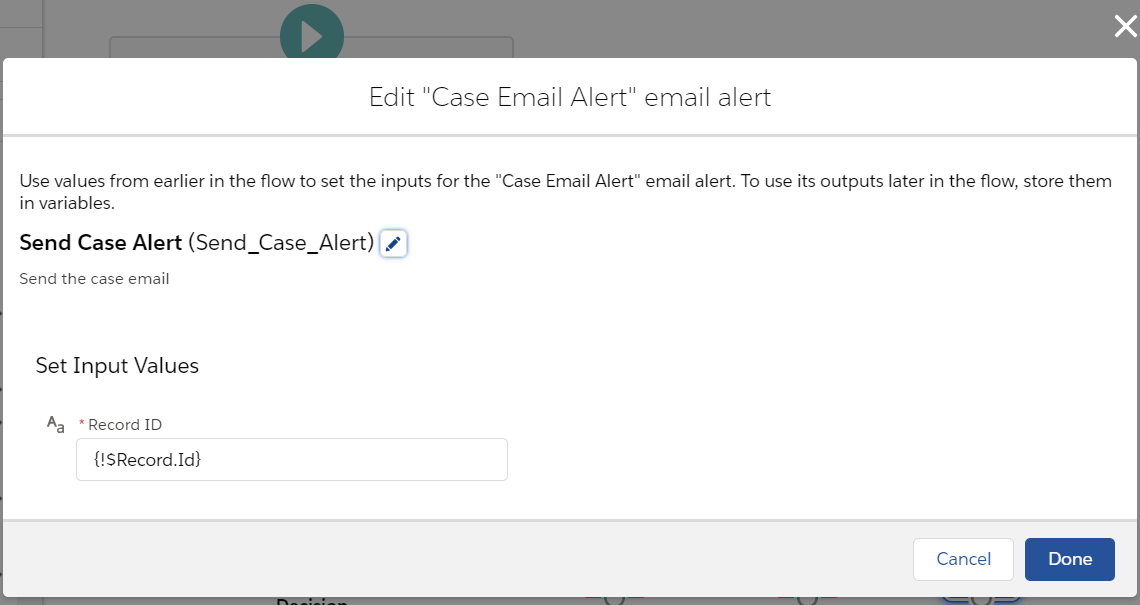
For the second immediate action in process builder, we need to send an email alert Case_Email_Alert.
Switching over to flow builder, we will use the Case Email Alert email alert and set the Record ID to {!Record.Id}.
If you have fairly simple processes for new record creations, you can possibly start moving your processes to the new after record save record creation flow trigger.
I don’t chase new shiny objects, as they aren’t usually mature on their initial release, so I’d recommend watching this feature for a couple of releases as they improve it before you start moving processes to flow.

I agree on this one! It shows promise and is heading in the right direction. We really do need that ischanged operator. I have used the before update in Orgs – again, knowing its limitations will help, but the before update is a great way to change fields when you know that the changes impact process builder, and not having to worry about the order things run in the process builder.
I am sure that they will get this where we need it to be!
LikeLike
I might be missing something and understand this is not key topic, but your use case of updating case priority if its origin is web seems more of Before Save flow. Updating same record after will trigger after update things again. I think by moving process builder to before save will improve things. Otherwise don’t see much value in moving process builder to after save.
LikeLike
Process builder is an after record change automation, not before record save.
LikeLike
Hi Jen – Is there a way to debug this type of flow since there are no input variables?
LikeLike
I don’t believe so. I think you would have to test this like you do a process, by making changes to the record. Perhaps it is on the roadmap?
LikeLike
Regarding ISNEW, wouldn’t the context of “Trigger: A record is created + Run Flow: After the record is saved” indicate that it is a new record?
LikeLike
The issue is when you select the A record is created or updated and after record is saved option. There is no way to tell in flow whether the record is new or not.
LikeLike
Thanks Jen, just been battling to find out if record changed, good to get confirmation that it’s not just me!
Phil – Regarding debug, I post a Chatter message to myself. Add an ‘Action’ element and choose ‘Post to Chatter’. Create a ‘Text Template’ variable for multi line text showing value of variables etc and reference that variable in the Action element. For Target Id use $User.Id.
You can’t add an Action to a ‘Before-Save’ Flow though 😦
LikeLike
I like that Mike! I have been known to build two very similar flows (or use “Save as new flow” and do some modifications) just for debugging. Have also used the email action. Another tool for debugging!
LikeLike
It appears as though there is a workaround to the subflows missing. According to ForcePanda, you can utilize actions to initiate a subflow. See his post: https://forcepanda.wordpress.com/2020/08/19/flow-action-call-subflow/
LikeLike
Nice blog, but I’m confused as to why you had to create another decision node and not simply add another outcome to the same decision for ‘case reason’?
LikeLike
This is meant to mimic the setup of a process to flow.
LikeLike